
1.JVM通俗理解
JVM是java虚拟机,可以在任何拥有jvm的平台运行java的字节码文件【.class文件】,JVM实现了java跨平台特性。
代码被编译成.class文件,JVM将.class文件转换成字节码(加载:将字节码转换成二进制字节流加载进入内存)来执行
2.重点理解:JVM内存机制
JVM的内存组成 ?
(1)堆:一块内存,被所有线程共享。存放【生成的对象】
所以为什么会有堆内存占满的问题出现,和对象内存回收有很大关联
(2)栈:虚拟机栈和本地方法栈
虚拟机栈:线程私有,存放【基本类型变量+对象引用变量】
包装类型(Integer,Character)都是普通对象,放堆内存
创建完对象,这个对象名作为变量存在这里 栈中数据是共享的
本地方法栈:为虚拟机中使用的Native方法服务
虚拟机栈为虚拟机执行Java方法(字节码)服务
栈的深度如果超过虚拟机允许的深度,抛出StackOverflowError异常
扩展虚拟机栈时,扩展无法申请到足够的内存 抛出OutOfMemoryError
【这里OOM依旧和内存是否充足有关】
(3)方法区:存放.class字节码文件,包含所有虚拟机加载的类、常量、静态变量等,存的都是整个程序中唯一的元素(static变量、class)
(4)程序计数器:线程私有的,理解为:维护当前这个线程执行的字节码的行号
2. JVM内存模型
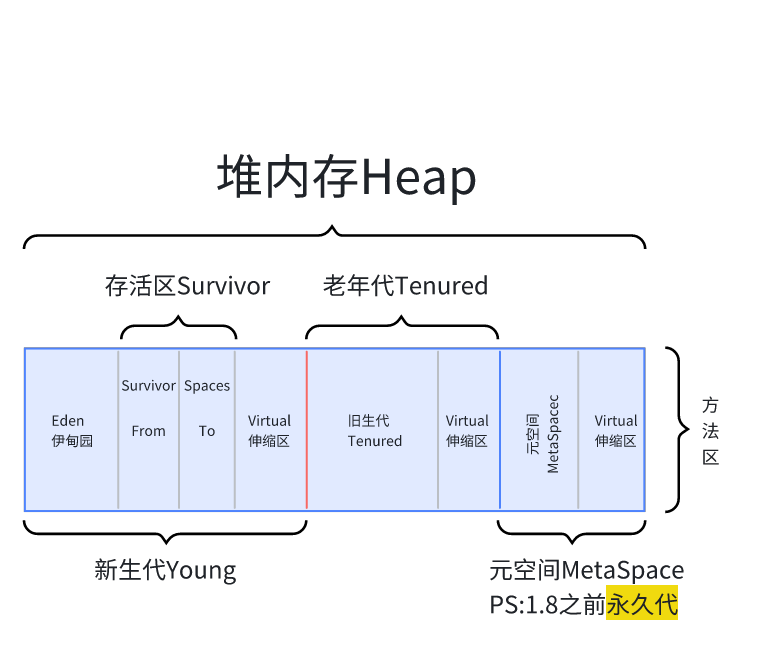
jdk1.8之后JVM内存模型将永久代替换--元空间,常量池依旧在方法区
垃圾回收机制是这样的:
(1) 新产生的对象放在Eden区里
(2) eden区满了,存活的对象复制到from区中
【如果存活对象from放不下,这些存活对象全部进入老年代,之后的eden区内存回收掉】
(3) 继续分配到eden,eden再次满了 eden+from 存活对象复制到to区
【to满则进入老年代,eden/from 内存都回收】
(4) 默认情况,一个对象复制15次,就进入老年代
(5) 老年代满了或放不下,进行一次full GC
垃圾回收
1.Minor GC /young GC
新生代回收:不影响老年代,需要速度快:复制算法
2.Full GC
老年代回收:整个堆的内存回收,标记-清除,标记-压缩
垃圾回收算法常见的几种:
(1) 复制算法:
整个内存空间被分两部分相同大小,每次使用一块空间,一半空间的内存占满后,将所有被引用的存活对象复制到另一块空间,然后情况当前空间;缺点是可用空间变小,且复制大对象效率低,不适合老年代
从根集合节点扫描,标记所有存活对象,将这些存活对象复制到一块新的内存,然后把原来的内存回收
eden:from: to 一般是8:1:1,eden满了则把对象复制到from ,然后回收eden内存,eden/from 满了则复制到to,然后回收eden/from
(2) 标记-清理 算法:
先从根节点开始 标记所有对象,没标记的就是未被引用的对象,清除阶段,清除所有的未标记对象
【适合清除老年代,但容易产生内存碎片,扫描空间两次(标记/清除)】
(3) 标记-压缩 算法:
先从根节点做一次标记,然后把存活对象压缩到内存的一段
清除阶段:清理边界外的所有空间,减少了碎片内存产生
(4) 分代收集算法:
Java 堆分为新生代和老年代,根据各个代的特点选择合适的垃圾收集算法。新生代-复制算法;老年代-标记压缩
新生代中,每次收集都会有大量对象死去,所以可以选择“复制”算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。
老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集
垃圾回收器 CMS和G1
(1) CMS:
基于标记-清除法的垃圾回收器
在启动 JVM 的参数加上“-XX: + UseConcMarkSweepGC”来指定使用 CMS 垃圾回收器。缺点是容易产生内存碎片,且需要更多CPU资源和更大堆空间
步骤分为四步:
1.初始标记:虚拟机停顿执行的应用线程,扫描对象然后标记
2.并发标记:用户线程和GC线程并发执行,继续向下标记对象
3.重新标记:再次暂停执行的线程【STW】,重新从根对象开始查找并标记遗漏的对象
4.并发清理:应用线程和GC清除线程并发回收,随后进入并发重置,重置CMS收集器的数据
(2) G1回收器
局部的标记-清理 根据哪快内存垃圾数量最多,回收收益最大作为衡量标准。
初始标记:标记所有直接关联对象
并发标记:堆中的对象进行标记,标记线程与应用程序线程并行执行,并且收集各个region的存活对象信息
最终标记:标记那些在并发标记阶段发生变化的对象,最终将被回收
清除:清除空region,即无存活对象的region
区别:
CMS是获取最短回收停顿时间为目标的收集器,减少老年代回收的停顿时间
一边运行一边并发标记,最后暂停清理,标记-清理易产生内存碎片
G1是把内存分成块,在可控时间内(比如最多停200ms),优先回收垃圾最多的小方块(Region)
【G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region】
根据标记结果,选择回收价值最高的(最大的Region)复制存活对象到新区域,然后回收旧区域内存
G1采用标记-复制算法 且可预测清理时间
3.类加载机制
(1)类加载机制:
依据.class文件,首先将class文件转换为二进制字节码加载到内存中,对其进行校验,准备,解析,初始化,最后转换成JVM可用的类型
(2)类加载过程
加载:加载类的二进制字节码(.class)到内存,结构化静态存储结构,生成class对象
连接:分为 验证-准备-解析
验证:检查类文件格式是否符合 JVM 规范【文件格式解析;元数据解析;字节码解析;符号引用解析】
准备:为类的静态变量分配内存并设置默认值。
解析:将符号引用替换为直接引用。
初始化:静态方法块和静态变量初始化【执行类的构造方法】
(3)双亲委派机制:
类加载器收到加载一个类请求,先将请求委派到类的父 类加载器,无法找到并加载则继续委派到上层 父 类加载器 ,直到顶层加载器
父类加载器无法加载才尝试子类加载器
打破双亲委派:重写classloader中的loadclass方法 ,或热部署
如 SPI 是 Java 的一种扩展机制,用于加载和注册第三方类库,常见于 JDBC、JNDI 等框架。
双亲委派模型会优先让父类加载器加载类,而 SPI 需要动态加载子类加载器中的实现。使用 SPI 机制通过 META-INF/services 文件指 定服务提供者的实现类。